Saindo do Pivotal Tracker para o Fulcrum. Bom o Suficiente.
Venho escrevendo aqui no blog sobre como estou montando minha própria infraestrutura interna. Já contei como saí do GitHub e Travis para o GitLab, depois como migramos do Slack para o Rocket.chat, mas a primeira migração de todas é o tema deste artigo.
Uso o Pivotal Tracker desde 2010 até 2015, e isso porque eu acredito que ele é muito superior ao Trello e outras listas de tarefas glorificadas por aí.
O Dilema do Custo
Como em todos os outros relatos, vou começar pelo argumento do custo. O Pivotal Tracker tem preço baseado na quantidade de usuários.
Se você tem um time pequeno e poucos clientes externos, um plano básico de 10 usuários já resolve, e você vai pagar apenas USD 420 por ano. Simplesmente pague e pronto.
Se você tem até 25 usuários, ainda continua barato, e sai por USD 1.800 por ano. Vale muito a pena.
Mesmo se você tiver 50 usuários, o plano máximo, você vai pagar USD 3.600 por ano. Acima disso, precisa entrar em contato direto com eles.
O custo está longe de ser proibitivo e, se você puder pagar, meu conselho é que pague.
No meu caso, a estratégia é ter controle total sobre nossos dados e conhecimento, e por isso prefiro ter a propriedade do serviço.
E como o Fulcrum estava “quase” bom o suficiente, resolvi testar e ver se conseguíamos evoluí-lo com o tempo. Acredito que, mesmo estando ainda muito longe do Tracker completo, o que temos hoje já atende à maior parte dos nossos projetos.
Deixa eu repetir: provavelmente você não vai ganhar nada com isso se seu time for pequeno. O Pivotal Tracker continua sendo, até hoje, a melhor ferramenta de gestão de projetos para times de desenvolvimento de software, e você deveria testá-lo primeiro, se acostumar com o fluxo dele (como vou explicar abaixo), e só depois decidir se quer assumir o controle e instalar a alternativa open source.
Tem o fator custo, claro, mas ele não é o incentivo principal para essa mudança.
As Funcionalidades Importantes
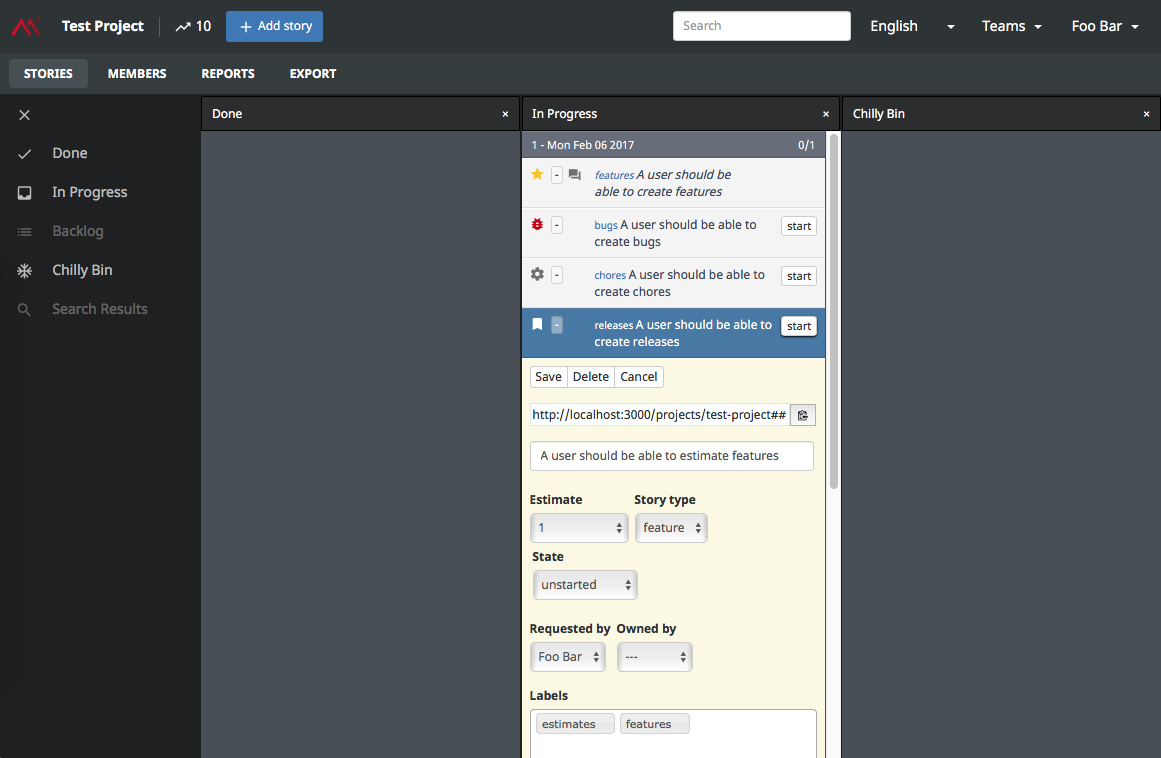
Pesquisando um pouco, encontrei o projeto Fulcrum. É um projeto Rails muito simples, muito bare-bone, que imita as funcionalidades mais importantes do Tracker.
Qualquer ferramenta competente de gestão de projetos precisa ter, no mínimo, 4 pilares:
- Stories (com threads de discussão, upload de arquivos, tags, organização em Epics e busca)
- Estimativa numérica adequada (story points, tamanho proporcional para as stories)
- Sprints com time-box (períodos curtos e fixos de tempo)
- Velocity (a produtividade real de um determinado time em um determinado projeto)
Qualquer ferramenta que tenha todos os itens acima já é útil.
O próprio Fulcrum tem quase tudo. Fizemos um fork interno do projeto e começamos a adicionar algumas das funcionalidades que faltavam. Já estamos usando ele há mais ou menos 1 ano e tem sido bom o suficiente para nossa rotina. Ainda há alguns bugs e funcionalidades faltando que pretendemos incluir.
Se você se interessar, estou disponibilizando esse fork publicamente para cumprir a licença Affero GPL.
Qualquer contribuição é bem-vinda.
Sobre Gestão Ágil Adequada
Desviando um pouco do assunto, quero explicar por que esse tipo de ferramenta (no estilo Tracker) é a melhor opção quando comparada ao que chamei de “listas de tarefas glorificadas”.
Os princípios são muito simples:
- Todo projeto precisa começar com o backlog mais completo possível (a incerteza está no seu pico no começo, e vão faltar detalhes, mas é importante ter uma visão do que significa “minimamente completo” e a ordem de importância de cada story, uma “prioridade” adequada).
- O nível de detalhe em si não importa. Uma story precisa ter informação suficiente para que qualquer desenvolvedor do time consiga implementar as tarefas necessárias. Caso contrário, ela deve ser marcada como “bloqueada”, para que o Product Owner saiba que precisa adicionar mais detalhes, e nenhum desenvolvedor encosta nela até que a tag seja removida.
- Todas as stories precisam ser estimadas (falo mais sobre isso na próxima seção). A unidade realmente não importa. Você pode pensar em horas, em frações de um dia ou no que ela realmente é: uma proporção. Uma story de tamanho “2” deveria ter aproximadamente metade da complexidade de uma story de tamanho “4”. É só isso. Até stories “bloqueadas” devem receber tamanho.
- Projetos precisam ser divididos em Sprints com tempo fixo e duração fixa, para que o time tenha a oportunidade de reavaliar frequentemente. É aqui que a estimativa pode ser refinada, onde mais níveis de detalhe nas stories devem ser exigidos.
- Bugs não podem ter estimativa numérica. Eles servem justamente para puxar a velocity do time para baixo, e são um indicativo de entregas mal feitas.
- Velocity é a quantidade real de story points entregues até o fim de uma Sprint.
- O total de story points de todas as stories do backlog do projeto dividido pela velocity do time dá uma “Data de Término” estimada por alto. Isso é importante, porque é assim que você sabe quando determinados grupos de funcionalidades serão entregues ao longo do tempo, e é isso que o Product Owner precisa saber para priorizar stories, simplificar stories ou até cortar funcionalidades desnecessárias.
- A única responsabilidade do Product Owner é prestar contas pelo Retorno sobre o Investimento das funcionalidades implementadas. E a única forma de medir custo-benefício é saber “quanto” uma funcionalidade vai “custar” em termos de story points divididos pela velocity.
O que a ferramenta vai expor:
- Se um backlog tem muitas stories “bloqueadas” ou muitas stories entregues sem aceitação, isso é sintoma de um Product Owner que não está fazendo o trabalho dele.
- Se a velocity varia demais entre sprints, isso é sintoma ou de stories mal escritas (e portanto desenvolvedores com dificuldade de entender o que fazer), ou de desenvolvedores sem concentração no trabalho e entregando resultados inconsistentes.
- Velocities inconsistentes com muitos bugs a cada sprint são sintoma de desenvolvedores que não estão fazendo código com qualidade adequada (testes automatizados para evitar regressões, por exemplo).
- Um “bug” não é a mesma coisa que o Product Owner mudar de ideia sobre uma story e rejeitá-la. O time não deve implementar mudanças não documentadas. A aceitação está amarrada ao que a story diz. O Product Owner precisa mudar de ideia antes da story ser implementada ou criar uma nova story para adicionar a mudança (e, portanto, adicionar mais custo ao projeto; não existe almoço grátis).
- Stories no “Chilly Bin” (no Fulcrum, ou “Ice Box” no Tracker) são “lista de desejos” e nunca serão implementadas até o Product Owner movê-las para o backlog.
- A velocity deveria ser aproximadamente a mesma entre sprints. Picos ou vales na velocity são sintoma de um problema que precisa ser atacado na próxima sprint. É assim que um projeto evolui para melhor ao longo do tempo.

Sobre Estimativa
Muita gente se preocupa demais com “estimativa correta” a ponto de criar tanta tensão que os desenvolvedores começam a gritar por “no estimates”. Isso é loucura. Por isso “estimativa” é uma palavra diferente de “previsão”: uma é incerta, um chute de grosso calibre, a outra é exata.
Não existe estimativa “correta”.
Eu diria que em muitos projetos, se as stories estiverem minimamente descritas (ou seja, um desenvolvedor consegue implementar o que está escrito), poderíamos estimar todas como tamanho “1” e esquecer disso.
Rodamos 2 ou 3 sprints (normalmente uma sprint deveria ser uma semana de trabalho - 5 dias de no máximo 8 horas, nem mais, nem menos) e medimos quantas stories foram entregues. E essa é a velocity.
Agora podemos ver quantas stories temos até o fim do projeto e dividir por essa velocity. E esse é o número de semanas que vamos levar para terminar o projeto.
Não há necessidade de estimativa por consenso.
Consenso em estimativas normalmente é desperdício de tempo. Estimativa é apenas a constatação de que é difícil escrever cada story no exatamente mesmo tamanho, e por isso adicionamos proporções a elas (uma story tamanho 2 é metade do tamanho de uma story tamanho 4).
Mas se um projeto tem 3 meses ou mais, menos as proporções importam (a menos que você caia na anti-prática de ter stories muito desproporcionais, algumas tamanho 1 e muitas tamanho 5, 8 ou até 10, por exemplo). Mas se você ficar abaixo de tamanho 5 para toda story, então quanto maior o projeto, menos as estimativas individuais importam. A velocity vai diluir as diferenças ao longo do tempo.
A tarefa do Project Manager, do Product Owner, do time em geral, é ficar de olho no total de pontos dividido por essa velocity, de onde sai a data estimada de término do projeto. E todos podem negociar, com antecedência, quais stories podem ser feitas, quais não podem, mudar prioridades, remover stories ou simplificar stories.
Não perca tempo tentando criar fórmulas para derivar consenso de estimativa.
Se você administra a Velocity, então você administra o projeto inteiro. Esse é o cerne de toda metodologia Ágil adequada. Todo o resto é acessório a essa finalidade.

Tentar aumentar a velocity artificialmente é um dos vários pecados. Você não consegue. É melhor investir tempo adicionando mais detalhes a uma story, ou simplificando uma story, ou decidindo que algumas stories simplesmente não são necessárias para entregar um produto decente no final.
Simulações de Monte Carlo, técnicas Six Sigma, conceitos de Kanban, nada disso importa. Todas as técnicas da indústria tradicional foram pensadas para linhas de produção de fábricas, onde o tempo de cada tarefa é bem definido e você administra a variância, a exceção. É um mundo Gaussiano, Normal.
Em projetos de software, ou qualquer trabalho artesanal e de pesquisa, você administra expectativas sobre resultados com base em marcos e cortando excessos e incertezas. É um mundo Pareto, onde não existe “média”, não existe meio, não existe variância.
Em um mundo Pareto, tudo está interconectado, e nada é estatisticamente independente (um requisito para Gaussianas). É portanto 80/20: onde 20% do projeto rende 80% dos resultados, onde 20% do escopo pode ser cortado.
Qualquer coisa que não seja “estatisticamente independente” (como jogar uma moeda) não pode ser tirada a média, não cabe em uma distribuição Normal. Provavelmente é uma Pareto, Power Law, Zipf, Exponencial, ou até uma Poisson, mas não uma Gaussiana. As partes de um software estão todas entrelaçadas em uma rede, elas não são eventos independentes, não podem ser reorganizadas aleatoriamente, elas não são facilmente intercambiáveis.
Conclusão
Este artigo é bem curto e eu posso expandir cada item acima em seu próprio artigo, bem longo. Me diz nos comentários se eu devo, e quais pontos levantam mais dúvidas.
Venho refinando essas técnicas ao longo dos últimos 10 anos, e pelo menos 5 deles dentro das restrições de uma ferramenta como o Tracker. E acredito que consegui chegar ao conjunto mínimo de princípios que levam a uma gestão adequada, longe de superstição, fantasia ou ilusão que você vê por aí hoje em dia.
Projetos sofrem quando as recomendações acima não são seguidas:
- Product Owners não cumprem suas responsabilidades: falham em adicionar detalhes às stories, negligenciam funcionalidades entregues e não as testam direito, não participam.
- Backlogs estão incompletos, com falta de detalhe, falta de estimativa, falta de priorização.
- Desenvolvedores não começam nem terminam suas tarefas direito, com qualidade de código adequada.
- Tempo é desperdiçado em bikeshedding em vez de entrega.
Nosso fork do Fulcrum, chamado “Central”, está longe de ser perfeito, mas funciona bem o suficiente e nos dá controle para continuar adicionando funcionalidades que tornam nossa rotina mais confortável, e estamos apenas começando.
Espero que essa técnica e essa ferramenta sejam úteis para mais times, e adoraria ouvir o feedback de quem se interessar.