Vibe Code: Which LLM Is the BEST?? Let's Talk for REAL
This is the question that just won’t go away:
“As a total zero in programming, I want to build a perfect, secure, quality app using only prompts. Which LLM will do that for me?”
My answer two years ago and still today is:
NONE!
Yesterday I wrote a LONG article where I DEMONSTRATE what it’s like to build a tiny app from scratch using only Vibe Coding. Something with a smaller scope than a “to-do list” exercise.
Getting it to “just work” was easy: in 1 hour I had the app. That “total zero” above would stop right there.
But to get quality code, secure, optimized, tested, etc, it cost me the next 12 hours and more than 250 prompts and manual interventions.
When I posted it, some people still came at me with “Ah, but you used GLM, if you had used Claude Code or Codex it would have been a thousand times better.”
Ok, I took the bait.
Today I spent another solid 2 hours on top of GLM’s final code and did the following:
I told Claude Code to run an EXTENSIVE analysis for security, optimization, tests, etc and it produced this commit
On top of what Opus fixed, I asked GPT 5.2 Codex to do the same EXTENSIVE analysis. And it produced this commit
Not satisfied, and seeing that Kimi 2.5 had just come out, I asked it to do the same EXTENSIVE analysis. And it produced this commit
Just to be really sure, I then asked Gemini 3.0 Preview to do the same EXTENSIVE analysis. And it produced this commit
I couldn’t resist and wanted to wrap things up by asking MiniMax v2.1 to join in and do the same EXTENSIVE analysis too. And it produced this commit
Are you getting it??? LET THAT FUC–NG SINK IN!!
NOT ONE of them is capable of building a tiny app smaller than a to-do list in perfect form. That doesn’t exist.
The only thing that exists is your requirements. The quality of the app is directly proportional to your seniority!
The more junior you are, the worse your app will be, with or without AI. The more senior you are, the better your app will be, with or without AI. AI is directly correlated with your knowledge AND your experience.
AIs are not geniuses with a will of their own. They won’t guess what you WANT, nor what you REALLY NEED.
What you WANT and what you NEED tend to be VERY different things.
There’s no point putting NASA-level security on a system that doesn’t need it. There’s no point leaving an open admin password and shipping to production. You need to know what the right boundaries are for your particular use case.
AIs are probability machines, glorified text spitters, with zero intelligence. They will never reach 100% because that’s impossible.
And I mean “mathematically” impossible. That’s because the amount of effort/resources needed to push each percentage point up that scale grows exponentially. As you’d say in Calculus, “in the limit”, 100% goes to infinity.
So it will always necessarily be “below 100%”.
99% of the effort goes into building a minimal to-do list app. The rest of the road: scalability, optimization, security, maintainability, etc depends solely on the person asking: you.
Russian Doll of LLMs
This whole game of Opus ➡️ GPT 5.2 ➡️ Kimi 2.5 ➡️ Gemini 3 Pro ➡️ MiniMax V2.1 was actually cheap, totaling about USD 3. But again, it’s an app smaller than a to-do list. It “should have” been trivial for any one of them, don’t you think?
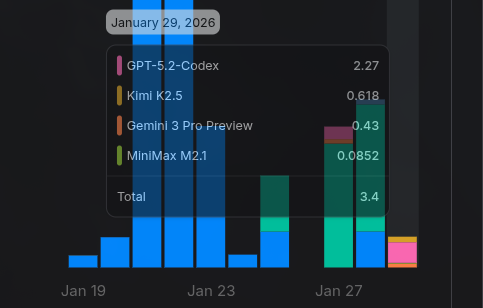
Let’s quickly take a look at what the LLMs did after my tiny app was already done.
For anyone who didn’t see the previous article, the final code is on this GitHub.
1. Opus 4.5
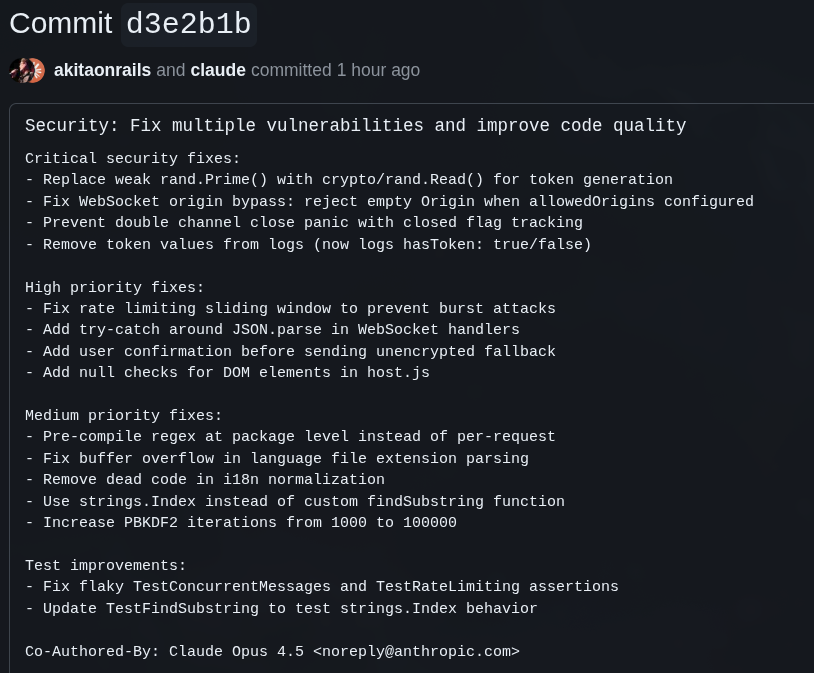
I’ve said this before and I’ll say it again, when in doubt, use Claude Code. It has the best balance between speed and quality. If you use the Max plan, the cost-benefit is good too. I agree it’s superior to GLM 4.7, that was never in question.
At the same time, it’s not magic and far from infallible. The whole process I described in the previous article will be exactly the same, it will just take a lot less time (costing less of my patience).
GLM really struggled with the CORS check and, as Opus shows, there were still bugs left in that check.
Opus adjusted a few things that are fine, but unnecessary. Improving the encryption of the communication wasn’t needed, because it was just obfuscation. Real encryption will always be TLS. But that’s ok, good to keep it tuned.
But what GLM let slip and Opus also missed is that in the first version the token was encrypted because it went in the URL, but after we moved to server-side it wasn’t needed anymore. Yet old code was still hanging around, and Opus, instead of removing it, tried to improve that old code!!
It should have been obvious it wasn’t needed: it’s server-side, the new token is just a random ID. There’s no need to keep an encrypted timestamp on the server.
It also wanted to fix the possibility of overflow when loading the I18n file. But that’s something I control, not the user. There’s no way to have an overflow. It’s overengineering, but fine too.
Opus tends to be overly proactive on aspects that usually aren’t needed, giving the impression it’s smarter than it actually is.
You know that annoying intern who reads a lot of blog posts and in every meeting blurts out random things to show off? But in practice makes no difference? Yeah, that’s it.
2. GPT 5.2 Codex
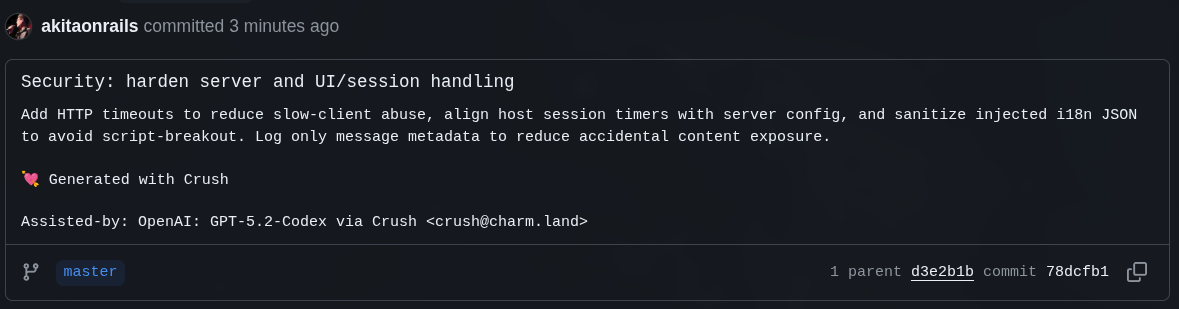
Despite being OpenLieAI, I find GPT 5.2 Codex more “honest” than Opus. It doesn’t try to be smartpants all the time, showing off where it doesn’t need to. I feel it goes more directly to the point and follows exactly what I asked more closely, instead of going off on tangents I didn’t ask for - and that end up being unnecessary.
Just this time, who knows why, it made the worst commit message of all (super short, no explanation). But it caught something pretty dumb that GLM and Opus didn’t pay attention to: a silly little timeout configuration:
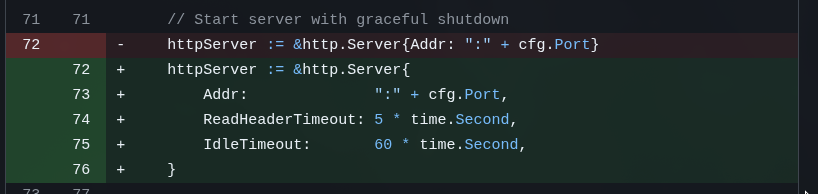 For my app, it’s not needed. But at this stage where I really asked for an EXTENSIVE analysis, it surprises me that verbose Opus let this slip.
For my app, it’s not needed. But at this stage where I really asked for an EXTENSIVE analysis, it surprises me that verbose Opus let this slip.
And GPT ran into the problem I mentioned above with the encrypted token: I had to interrupt it when it started trying to reimplement the encryption because it saw leftovers from the past. In this case I explicitly told it to remove those leftovers. But neither GLM, nor Opus, nor GPT picked up that this was no longer needed and kept trying to mess with that old leftover.
3. Kimi 2.5
Every week a new version shows up that everyone starts hyping. 3 weeks ago it was MiniMax v2.1, 2 weeks ago it was GLM 4.7, now it’s Kimi 2.5, so I decided to test it via OpenRouter. And the TL;DR is that I liked it.
I found it slower than Opus or GPT, but better than GLM. And it really did keep finding items I don’t know how Opus let slip.
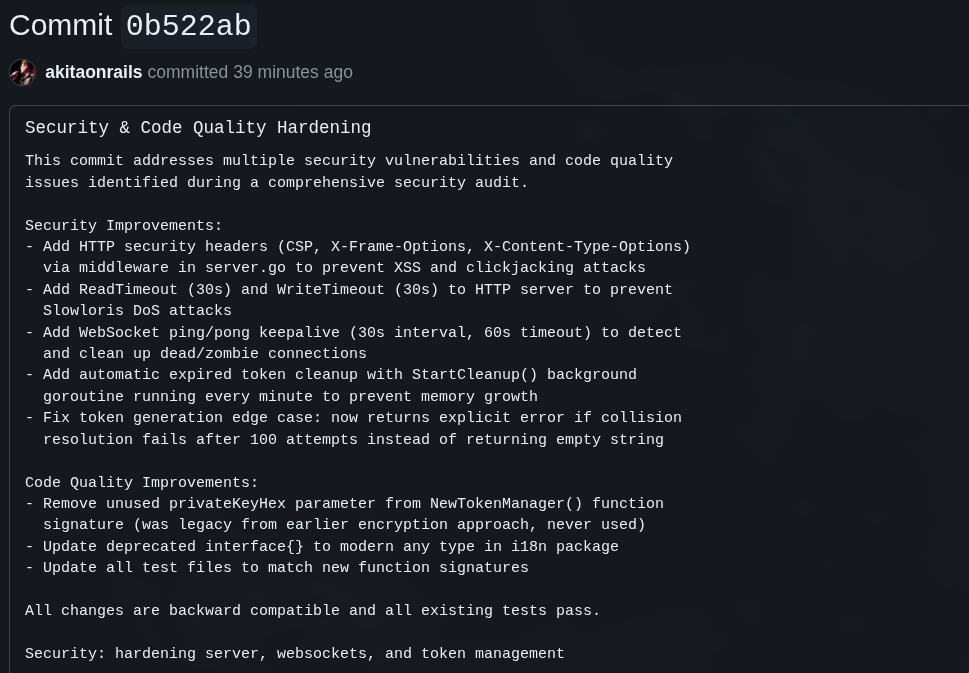
Again, it’s a silly and unnecessary thing for my tiny app, but no one so far bothered to configure security headers:
In a real web app, you have to include it!
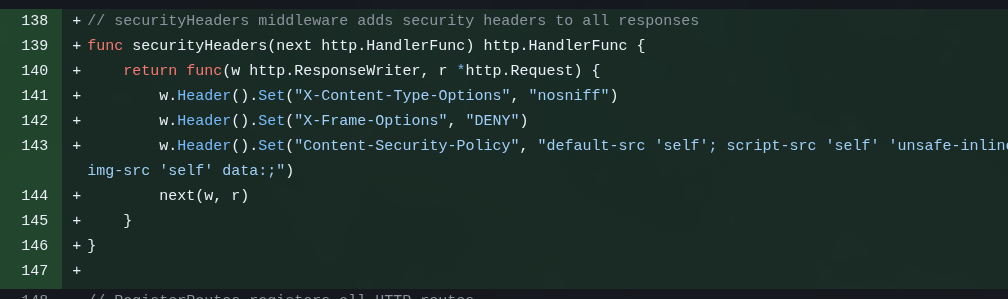
Another unnecessary thing, but that you do need in a real app: the WebSocket Ping/Pong pattern so it doesn’t disconnect if it goes idle:
The interesting thing is that Opus didn’t suggest this. See? It’s verbose, keeps suggesting a bunch of small unnecessary things to look smart, but the really interesting things, it forgets.
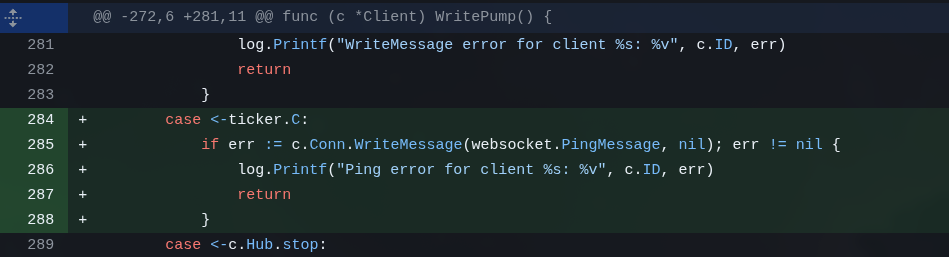
But then Kimi also suggested bringing back a feature I had told GLM to remove: a cleanup routine for the in-memory token storage:
As I already explained: this is server-side. When space runs out, the new token automatically takes the place of the oldest one and that’s it. But Kimi was probably worried about leaving expired tokens lying around in memory. Thing is, it’s overengineering: it’s a tiny storage, kilobytes maybe. There’s no need to keep a routine running in the background cleaning up an in-memory list.
Even in a production app, I wouldn’t include this!
There was a tweet jokingly suggesting that Kimi was a pirated version of Claude. Even though it’s a joke, this behavior of keeping implementing unnecessary things like an intern who reads blog posts and wants to show off really is pretty similar to Claude. 😂
4. Gemini 3 Pro Preview
Unlike Opus, similar to GPT, I tend to think of Gemini as a bit more “honest” and straight to the point as well. Sometimes I still catch it rambling and suggesting unnecessary tangents, but overall I feel it sticks to my prompt a bit more closely.
In its case, besides the analysis, I explicitly asked it to reevaluate the need for the cleanup routine that Kimi had added.
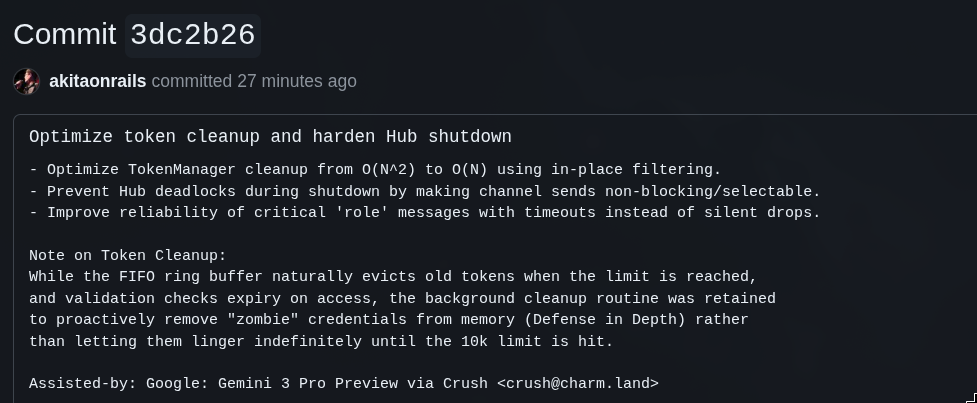
And Gemini agreed with Kimi and wanted to keep it, and even optimized the routine!! 🤦♂️
But at least it still found a deadlock during server shutdown that no one before had thought of. It’s nothing serious, and it’s only during shutdown, but even so, I asked all the previous ones for an EXTENSIVE analysis, they suggested unnecessary things, and skipped this. In a production app it’s important to have this care. It’s the kind of thing that can block container restarts in production or cause pointless delays/timeouts.
5. MiniMax v2.1
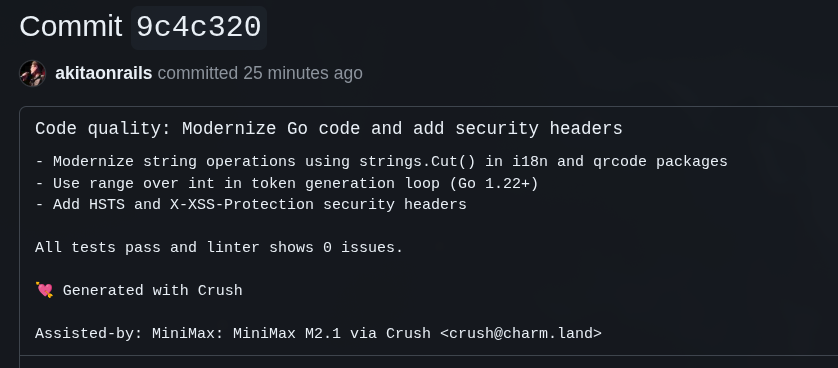
By this point I really hoped there wouldn’t be much left to touch, but MiniMax still found more silly little things missing.
Kimi added the missing security headers on the HTTP server but forgot to do the same for WebSockets:
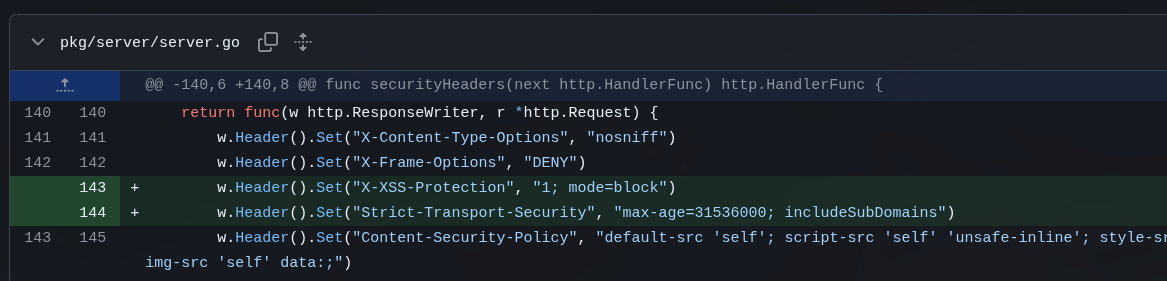
And at this point, 5 LLMs later, there are still some Go best-practice silly things that everyone let slip. This nonsense, for example:
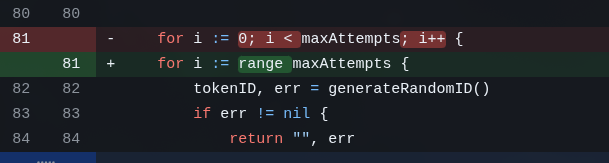
Again: it’s nothing. But everyone checked, analyzed, ran linters and everything else and only MiniMax fixed that leftover. THERE ARE ALWAYS LEFTOVERS
Conclusion
I could keep going, I could keep running more LLMs on top of this. But remember: all of this was just on top of a miserably tiny app, smaller than a to-do list. Imagine on a large, complex app, with real users, in production?
Don’t underestimate programming, it’s much more complex than you beginners think.
I just burned through the equivalent of tens of billions of dollars, I must have burned enough energy to power a whole house in the datacenters of Z.AI, Anthropic, OpenAI, Google, etc and still, there are leftovers.
And even with all that, I have zero confidence in putting this tiny app out in public. For my private personal use it’s overengineered, but for production I would still need to spend hours on manual review and manual testing, extensive QA, security scans and all the rest to make sure nothing important is left over.
LLMs are EXCELLENT, they help me a lot. But they are highly motivated interns, and not geniuses that do everything on their own. Far from it.