I Built a Data Mining System for My Influencer Girlfriend — Tips and Tricks
My girlfriend is an influencer in games, anime, cosplay and pop culture. She does interviews, covers conventions, produces content for several platforms, negotiates with sponsors. It’s a one-person professional operation with a lean team. And like every professional operation, she needs data.
The problem is that gathering data from social networks is grunt work. Open Instagram, YouTube, X, look at numbers, compare to competitors, check the events calendar, monitor sponsors, read comments, calculate engagement, decide how much to charge for a sponsored post. All manual, all repetitive, all eating time that should go to creating content.
I did what any programmer boyfriend would do: I built a full data mining system, with automated collection, LLM-driven analysis, and a Discord chatbot where she talks to the data in plain language.
This article isn’t about the code itself (the project won’t be open source). It’s about the build process, the decisions that only show up after you start, the technical tricks that saved the project, and why a wishlist document from your user is worth more than any functional spec.
Start with the Wish, Not the Architecture
The first thing I did was sit down with her and ask her to talk freely about what she wanted. No technical jargon, no form, no user stories. Her own words. I recorded it in an IDEA.md file that became the north star for the whole project.
What came out of it:
“My biggest difficulty today is figuring out what kind of content to make that can really take off and why the ones that worked actually worked, what made them get the result they got. I have to read the comments on the videos to get a general sense of why.”
“How much I should/could charge for a sponsored post, based on engagement research, competition, sponsors, events.”
“How to make a sponsored post that doesn’t look like a sponsored post — paid content that brings engagement without looking like just a sales pitch.”
She didn’t ask for a dashboard. She didn’t ask for charts. She didn’t ask for PDF reports. She asked for answers to concrete day-to-day problems. That completely changed how I approached the architecture.
If I had started from a technical spec, I’d have built an analytics platform with pretty charts and CSV exports. The system she actually needed was something more like an assistant that knows the data and answers questions in Portuguese.
The IDEA.md also listed initial competitors and sponsors. Brands she could work with (themed restaurants, figure shops, Crunchyroll, Piticas, Fanlab). Reference profiles on Instagram. All of it became seed data. The document wasn’t a spec — it was a conversation that turned into organic requirements.
58 Commits in 3 Days
The project was built in 3 days. Not 3 weeks, not 3 months. 58 commits, 3 distinct phases:
Day 1 — The Data Engine. 12 commits. Rails 8 scaffold, models, collectors for YouTube/Instagram/X, LLM integration. Discovery pipeline to find new profiles automatically. Per-post performance scoring. Sentiment analysis of comments via Claude. By the end of the day, the system was collecting data from all 3 platforms and classifying every post as viral, above average, average, below or flop.
Day 2 — The Brain and the Voice. 35 commits. The most intense day. Two big subsystems showed up: the “Oracle” (tracking events, conventions, game/movie/anime releases, news) and the Discord chatbot with tool calling via RubyLLM. Also production hardening, Docker, deploy guide. And a big pivot: I swapped the weekly email report for 5 daily Discord digests.
Day 3 — Entertainment and Resilience. 11 commits. Steam games (Store API + SteamSpy), AniList for tracking seasonal anime, growth analytics, image generation via Gemini, an auto-healing system for broken URLs.
The final numbers:
| Metric | Value |
|---|---|
| Files | 430 |
| Total lines | 37,088 |
| Lines of Ruby | 25,562 |
| Tests | 916 (0 failures) |
| Models | 17 |
| Scheduled jobs | 25+ |
| Bot tools | 40+ |
| YAML prompts | 23 |
| External integrations | 12+ APIs |
These numbers aren’t to my credit. Claude wrote a good chunk of the code. But the direction, the architectural decisions, and especially the validation of every step were human. Claude doesn’t know what a Brazilian cosplay influencer needs. Neither did I — but she told me.
The Architecture That Emerged
The final system is a headless Rails 8. Zero web interface. No views, no real controllers (just /up for the health check). All functionality is delivered via background jobs, rake tasks, and the Discord chatbot.
The stack:
- Rails 8.1 with Solid Queue (jobs) and Solid Cache
- SQLite3 in production (WAL mode, bind mount between containers)
- RubyLLM for integration with Claude Sonnet via OpenRouter and Grok
- Ferrum for scraping with headless Chrome
- Discordrb for the chatbot
- Docker Compose with 4 services
The docker-compose.yml ended up lean:
x-app: &app
build: .
env_file: .env
restart: unless-stopped
volumes:
- ./data/storage:/rails/storage
services:
app:
<<: *app
ports:
- "127.0.0.1:3000:80"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:80/up"]
deploy:
resources:
limits:
memory: 512M
jobs:
<<: *app
command: bundle exec rake solid_queue:start
depends_on:
app:
condition: service_healthy
deploy:
resources:
limits:
memory: 1G
discord:
<<: *app
command: bundle exec rake discord:start
depends_on:
app:
condition: service_healthy
chrome:
image: chromedp/headless-shell:stable
deploy:
resources:
limits:
memory: 1G4 containers: app (Puma, basically just the health check), jobs (Solid Queue running 25+ scheduled jobs), discord (the bot), and chrome (headless browser for scraping). All state lives in SQLite via a bind mount on the host. No Redis, no Postgres, no extra infrastructure.
Idempotency Above All
If I had to pick one concept to summarize this project, it would be idempotency. Every job can run twice in a row without creating duplicates, without corrupting data, without side effects.
The base pattern:
module Collection
class BaseCollectorJob < ApplicationJob
SNAPSHOT_DEDUP_WINDOW = 1.hour
retry_on StandardError, wait: :polynomially_longer, attempts: 3
def perform(profile_id: nil)
scope = profile_id ? SocialProfile.where(id: profile_id) : profiles_to_collect
scope.find_each do |profile|
log = find_or_create_log(profile)
begin
items = collect_for_profile(profile)
profile.touch(:last_collected_at)
log.update!(status: :completed, items_collected: items || 0)
rescue => e
log.update!(status: :failed, error_message: "#{e.class}: #{e.message}")
raise if should_raise?(e)
end
end
end
def upsert_post(profile, attrs)
post = profile.social_posts.find_or_initialize_by(
platform_post_id: attrs[:platform_post_id]
)
post.assign_attributes(attrs.except(:platform_post_id))
post.save!
post
end
def record_snapshot(profile, metrics)
return if profile.profile_snapshots
.where("captured_at > ?", SNAPSHOT_DEDUP_WINDOW.ago).exists?
profile.profile_snapshots.create!(captured_at: Time.current, **metrics)
end
end
endTwo protection mechanisms: find_or_initialize_by(platform_post_id) for posts (upsert, not insert), and SNAPSHOT_DEDUP_WINDOW for snapshots (skip if we already collected one in the last hour). If the job crashes mid-run and Solid Queue requeues it, nothing duplicates.
Scraping errors (BlockedError, RateLimitError) get swallowed silently — retrying doesn’t help, the rate limit needs to cool off, and getting blocked is expected. Real errors (database, network, bugs) bubble up to the retry with polynomial backoff.
This decision to “swallow certain errors” feels wrong until you run the system for a week and see that Instagram blocks one in every 5 collection runs. If every block triggered 3 retries with exponential backoff, the system would be perpetually behind.
nil vs Zero
This is one of those conceptual bugs you only discover with real data. When Instagram doesn’t return the share count for a post (because the API simply doesn’t expose that field), should the value be nil or 0?
The difference matters. nil means “we don’t have this data”. Zero means “we have the data and it’s zero”. If you treat nil as zero, the LLM analysis concludes that nobody shares posts on Instagram — which is false. The API just doesn’t expose that metric.
I built a reusable prompt snippet just for this:
When a field is null: don’t say “0 likes” — say “data not available for this platform”. When comparing platforms, warn that certain metrics aren’t comparable. When it’s zero: report it normally — the data is real and confirmed by the API.
That snippet gets included in every prompt that handles numeric data. Without it, the LLM happily mixes “not collected” with “actually zero” and draws wrong conclusions.
The Headless Chrome Trick: Host Header Bypass
The project uses chromedp/headless-shell in a separate container for scraping. Works perfectly. Until you try to connect Ferrum (the Ruby Chrome automation gem) to it over Docker networking.
The problem: chromedp/headless-shell uses a socat proxy on port 9222 that rejects any request whose Host header isn’t localhost or an IP. When Ferrum tries to connect to http://chrome:9222, the Host header goes out as chrome:9222, and socat refuses.
The fix was to discover the WebSocket URL manually, forging the header:
def discover_ws_url(chrome_url)
uri = URI.parse("#{chrome_url}/json/version")
req = Net::HTTP::Get.new(uri)
req["Host"] = "localhost" # bypass
response = Net::HTTP.start(uri.hostname, uri.port) { |http| http.request(req) }
data = JSON.parse(response.body)
ws_url = data["webSocketDebuggerUrl"]
return nil unless ws_url
# WS URL points to 127.0.0.1 inside the container — swap it for the reachable hostname
remote_uri = URI.parse(chrome_url)
ws_url.sub(%r{://[^/]+}, "://#{remote_uri.host}:#{remote_uri.port}")
endI do the GET to /json/version with Host: localhost to slip past socat. I get the WebSocket URL back (which points at 127.0.0.1 — useless from outside the container). I rewrite the hostname to chrome:9222 (the service name in Docker Compose). I hand the ws_url straight to Ferrum, which opens the WebSocket without going through socat’s HTTP layer.
This kind of thing doesn’t come to mind upfront. You discover it after 1 hour of connection refused and reading the source code of chromedp/headless-shell.
Tool Calling: The Bot That Queries the Database on Its Own
The coolest part of the project is the Discord chatbot. She types a question in Portuguese (“how were my posts this week?”) and the bot calls the right tools, queries the database, and answers with real data.
The secret is RubyLLM’s tool calling. Every tool is a Ruby class with description and params:
class PostPerformanceTool < RubyLLM::Tool
description "Returns post performance stats: baseline, " \
"breakdown by content type, best times, best hashtags."
param :username, type: :string, desc: "Profile username (e.g. milaoliveira.png)"
param :analysis, type: :string,
desc: "Type: baseline, content_types, timing, hashtags",
required: false
def execute(username:, analysis: "baseline")
profile = SocialProfile.find_by(username: username.to_s.strip)
return "Profile '#{username}' not found." unless profile
case analysis.to_s.strip.downcase
when "baseline"
baseline = PostPerformance.compute_baseline(profile)
{
username: profile.username,
post_count: baseline[:post_count],
mean_views: baseline[:mean_views].round(0),
stddev_views: baseline[:stddev_views].round(0),
mean_engagement: baseline[:mean_engagement].round(2)
}
when "timing"
PostPerformance.timing_breakdown(profile).first(10).map do |entry|
{ day: days[entry[:day]], hour: "%02d:00" % entry[:hour],
avg_percentile: entry[:avg_percentile].round(1) }
end
# ...
end
end
endThe LLM gets the list of 40+ tools with their descriptions, decides which ones to call with which parameters, gets the results back, and formulates the answer. The Discord bot shows real-time status while it works: “Querying profile metrics… Checking growth… Analyzing post performance… (3 queries)”.
The trick was making each tool return structured data (Hashes and Arrays), not formatted text. The LLM is much better at formatting raw data into a conversational reply than at parsing semi-structured text.
Another detail that only showed up in real use: clamping parameters. When the LLM asks for limit: 999 on a parameter that maxes out at 50, instead of returning an error, I do [[val.to_i, 1].max, 50].min. The LLM gets parameters wrong more than you’d think. Every error generates a correction round-trip that costs tokens and time.
Composable Prompts: YAML > Hardcoded Strings
Every prompt in the system lives in YAML under config/prompts/. Each one has a system (fixed instructions), a template (with data interpolation), and optionally includes (reusable snippets):
module Llm
class PromptBuilder
PROMPTS_DIR = Rails.root.join("config", "prompts")
class << self
def build(name, data = {})
prompt = load_prompt(name)
base = load_prompt(:_base_context)
includes = resolve_includes(prompt["includes"])
system_parts = [base["system"], includes, prompt["system"]]
.compact.reject(&:blank?)
system_message = system_parts.join("\n\n")
user_message = interpolate(prompt["template"], data)
{ system: system_message, user: user_message }
end
end
end
endThe _base_context.yml carries info every prompt needs (who the influencer is, niches, audience, general guidelines). The snippets in config/prompts/snippets/ solve recurring problems:
null_vs_zero.yml— the nil/zero distinction explained abovenever_invent.yml— “NEVER invent data, only analyze what’s actually present”json_only.yml— “respond ONLY in valid JSON”
When a prompt needs any combination of these, you just list them in includes. No duplication, no risk of conflicting instructions across prompts.
This decision came out of a real bug: two different prompts gave contradictory instructions on how to handle null values. One said “use 0”, the other said “use null”. The LLM obeyed one or the other depending on the day. Centralizing in snippets killed off an entire class of inconsistency.
Discovery Pipeline: Autonomous Profile Mining
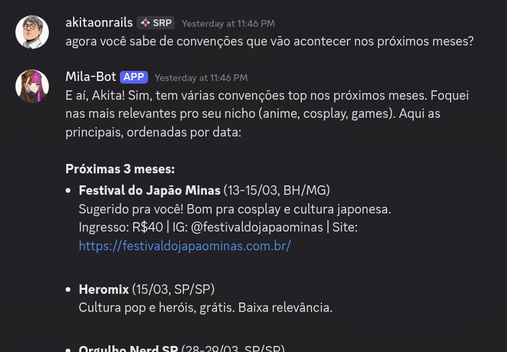
The initial system started from a manual list of competitors and sponsors. But the influencer lives in a dynamic ecosystem — new creators show up every week, brands appear and disappear. The discovery pipeline automates that.
It runs every Friday at 2 a.m. It starts by mining data we already have in the database: who’s being @mentioned in posts, who comments often and with high engagement, which profiles show up in bio links, who uses brand hashtags (#publi, #parceria), which Linktree links point to other creators. All pure SQL, no API calls, no rate-limit risk.
The candidates that come out of that get validated against the platforms’ APIs (does the Instagram exist? Is the YouTube channel real?), then enriched with cross-platform connections (if we validate an Instagram, we look for the YouTube and X of the same creator).
A batch LLM call evaluates all the candidates, classifies each one as competitor, potential sponsor or irrelevant, and assigns relevance and niche-fit scores. The top 3 become actually tracked profiles — the system starts collecting data from them automatically.
After that, it groups everything into Creator entities. The influencer is depth 0. Direct competitors, depth 1. Mentions of competitors, depth 2. Maximum 3 degrees of separation, to avoid infinite cascade.
From Weekly Report to Daily Digests: Listening to the User
The original plan was a weekly email report with 9 sections. But midway through I decided it would be more dynamic to not even leave Discord and have that information always available.
I pivoted to 5 daily digests on Discord:
- Monday — Performance Recap (followers, growth, top posts)
- Tuesday — Competitor Radar (snapshot, news, strategies)
- Wednesday — Content Playbook (schedule, trends, hashtags)
- Thursday — Opportunities and Pricing (brands, pricing, packages)
- Friday — Next Week (events, priority actions)
Every digest has numbered items with feedback buttons. She marks what she found useful and what she didn’t. That feedback feeds future analyses — the system learns which kinds of insight she values.
This change, which wasn’t in any plan, is probably what improved her experience the most. Every morning at 9 a.m. she opens Discord and gets a fresh, digestible, actionable summary. The weekly email got demoted to backup, commented out in recurring.yml.
The Oracle: Context the Algorithm Doesn’t See

Social media data without external context is kind of useless. “This post got 3x more views than average” is a fact. “This post got 3x more views because it dropped on the day the new Sonic trailer came out” is an insight.
The Oracle is the subsystem that provides that context.
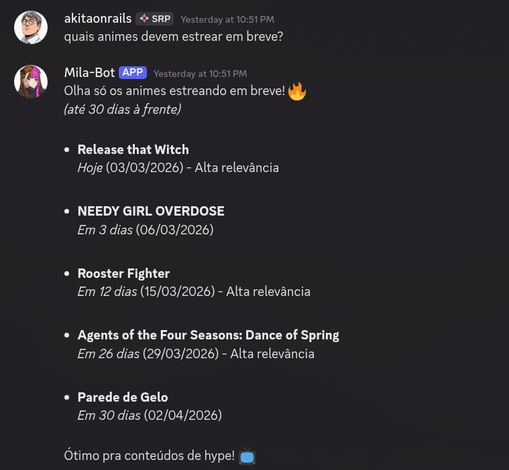
The most critical part is convention tracking: CCXP, Anime Friends, BGS, and dozens of other geek calendar events. Dates, prices, venues, ticket links, the event’s Instagram/X accounts. It monitors daily for changes (date moved, cancellation, guest announcement). The influencer plans her entire calendar around conventions. If CCXP changes its date, she needs to know that day, not the following week.
It also tracks movie/series releases via TMDB, games via IGDB (with Twitch OAuth), anime via AniList — all filtered for geek content, with a 90-day forward window. Franchise anniversaries (using TMDB, IGDB, AniList, Wikimedia) and Brazilian holidays with floating-date calculation. Yes, there’s an Easter calculator in the code based on the computus algorithm. And news via RSS and X/Twitter scraping every 6 hours, classified by relevance to the niche.
The event tracker scrapes convention sites with headless Chrome and uses the LLM at temperature 0.1 to extract structured metadata (date, price, venue). It has a regex fallback for Brazilian-format dates (“15 de março de 2026”). Deduplication by fuzzy name matching + date proximity — because “CCXP 2026”, “CCXP São Paulo 2026” and “CCXP SP” are the same event.
SQLite in Production: Yes, It Works
SQLite3 in production. With WAL mode, a single writer at a time is enough because the system has a predictable write pattern (sequential jobs, never concurrent in the same second). The data lives in a Docker bind mount (./data/storage:/rails/storage) and backup is cp data/storage/*.db backups/.
Rails 8 treats SQLite as a first-class citizen. Solid Queue and Solid Cache run on SQLite without issues. The overhead of a Postgres for a system that serves one person doesn’t justify itself.
25+ Scheduled Jobs
The config/recurring.yml has 25+ jobs with staggered schedules so the machine doesn’t get overloaded:
production:
youtube_collection:
class: Collection::YoutubeCollectorJob
schedule: every day at 3am
instagram_collection:
class: Collection::InstagramCollectorJob
schedule: every day at 4am
x_collection:
class: Collection::XCollectorJob
schedule: every 2 days at 5am
oracle_events:
class: Oracle::EventTrackerJob
schedule: every Monday at 2am
convention_monitor:
class: Oracle::ConventionMonitorJob
schedule: every day at 5am
discovery_pipeline:
class: Discovery::OrchestratorJob
schedule: every Friday at 2am
comment_sentiment:
class: Analysis::CommentSentimentJob
schedule: every Sunday at 5am
weekly_analysis:
class: Analysis::WeeklyAnalysisJob
schedule: every Sunday at 6amCollection runs in the early morning (3am-5am). The Oracle intelligence kicks off Monday at 2am. Discovery on Friday at 2am. Heavy analysis (sentiment, strategy) on Sunday when there’s no digest to deliver. Digests Monday through Friday at 9am, each day on a different theme. Maintenance (cleaning up finished jobs, URL health checks, aggregating old data) fills the gaps.
The pattern is deliberate: no heavy job competes with the morning digests. If the weekly analysis runs late, Monday’s digest still goes out because it uses Saturday’s collection data, not Sunday’s analysis.
What You Can’t Predict Without Running It
Some things I only found out after the system was in production.
Instagram blocks scraping at random. It doesn’t matter how stealth your browser is. The initial setup was scraping via Ferrum only. Right off the bat I added Apify as the primary source (paid API, more reliable) and the scraping became fallback.
LLMs hallucinate timestamps. I asked the bot to create a reminder for “tomorrow at 3pm” and it calculated a date in 2024. The fix was to inject current_datetime into every prompt that touches time and instruct it explicitly: “calculate based on current_datetime, convert to ISO 8601 with UTC-3”.
Discord has a 2000-character per-message limit, which seems obvious until your bot sends a 4000-char analysis and Discord just truncates it. I built an automatic split that breaks at the last \n before the limit.
Tool calls fail on parameters more often than I expected. The LLM asks for limit: 100 when the max is 50, or sends the username without the @ when it should have. Silent clamping ([[val.to_i, 1].max, 50].min) and input normalization (.strip, .delete("@")) on every tool killed off an entire category of errors that were burning tokens in retry loops.
Conventions change dates more than I imagined. I added an announcement system that tracks every change (date, venue, price, cancellation) with a timestamp. The event tracker runs every Monday, but the convention monitor runs DAILY, because the last thing the influencer wants is to find out a convention moved its date after she already booked the hotel.
The Bot as an Interface
The smartest decision in the project was not building a web interface. Discord is already where the influencer spends her day. The bot lives there, available any time. She types “what should I post this week?” and gets a contextualized answer with data from her own posts, from competitors, from the events calendar, from hashtag trends, and from the season’s anime/games.
The chatbot combines several tools into one answer. If she asks about content strategy, the LLM calls: content digest + events calendar + hashtag trends + seasonal anime + Steam games. Five database queries, all stitched into a conversational reply in Portuguese.
There’s even a “deep thinking” mode that activates when it detects words like “research”, “analyze”, “investigate”. In that mode, the bot uses ALL relevant tools, runs multiple queries, cross-references data across sources.
Conclusion
The whole project shipped in 3 days, from zero to production, collecting real data, sending out digests every morning. No Jira, no sprint planning, no 6-month discovery phase. An IDEA.md with the user’s wishes in her own words, iterative development commit by commit, and continuous validation with the person who’s going to actually use it.
If I had started from the architecture, I’d have spent weeks designing a dashboard she would never open. Starting from the wish, the system ended up being a Discord chatbot she uses every day. Async jobs that aren’t idempotent are time bombs — the rate limit is going to blow, the scraping is going to fail, the container is going to restart, and if the job can’t survive that without duplicating data, the system doesn’t work.
In the end, the measure of success for the project isn’t lines of code, isn’t the number of passing tests, isn’t elegant architecture. It’s the influencer opening Discord on a Monday morning and having what she needs to plan the week.